


Intro
Modern developers today have a great variety of technologies to achieve the same thing. As exciting as this is, it can also get overwhelming when choosing a stack for your next project.
The tools to develop APIs fall into this category. Many applications have long moved from the traditional REST APIs into ones like GraphQL or tRPC. But which one is right for your project and how should you decide about it?
This is a high overview of the two tools, where I am considering some of their main capabilities and basic setup. Ultimately, how much they matter depends on what you want to build.
🔭
First, some context
About a month ago, I was developing the authentication and onboarding pages of an MVP for the company I work for, using Next.js, GraphQL, Prisma and Supabase. This has been the stack for most of our projects and seemed quite an obvious choice here too: we have a platform where signed-in users can interact with other users, post messages, have a personalised profile page, etc.
Two weeks into development and the team lead had some concerns about the architecture of the project: I had already written a significant amount of code for just the basic functionality. I already had two schemas (GraphQL and Prisma) which I had to keep in sync, as well as be able to expand later on when we would add more features.
I should probably mention at this point we are a digital agency with a small developer team, which makes us even more aware in terms of keeping our applications sustainable and easily maintainable. This is how I was prompted to check into alternative API paradigms and more specifically into tRPC.
The game was on! 🚀
GraphQL
GraphQL is a query language for APIs, that provides a more flexible way to interact with API data compared to REST.
In a simple example where we have a user with properties like name, age, email, bio and avatar, we would typically have to make separate requests for each piece of information. If that user relates with other structures, the task becomes more complicated, in a case where they can be the authors of posts. All these entities are represented by different endpoints and combining data from some or all of them, requires multiple requests to our API.
With GraphQL, in a scenario like the above, we can make one single request. This tool lets us shape these three entities and their connections so we can tailor our queries to request only the data we need.
This is an efficient approach in terms of network traffic. We do not overload our server with requests to get all the posts from a specific user (author). Additionally, GraphQL provides a type system that allows us to validate the received data so that we know it is accurate and consistent.
Today, GraphQL is one of the most popular technologies in API development, used by many well-known companies like GitHub, Pinterest, Twitter, and many others. So, why should we look at other API solutions, like tRPC?
tRPC
Before we start talking about this tool, let's explore RPC.
What is RPC?
To approach tRPC, let's first examine the RPC part, which stands for Remote Procedure Call. This is a protocol that describes the interaction between a client and a server (or just two servers) and essentially allows a computer program to make a request to a function (procedure) on another computer of a different network. The other computer runs the called function and returns the results of this process to the requesting machine. It provides a way to communicate between different systems as if they were local procedures.
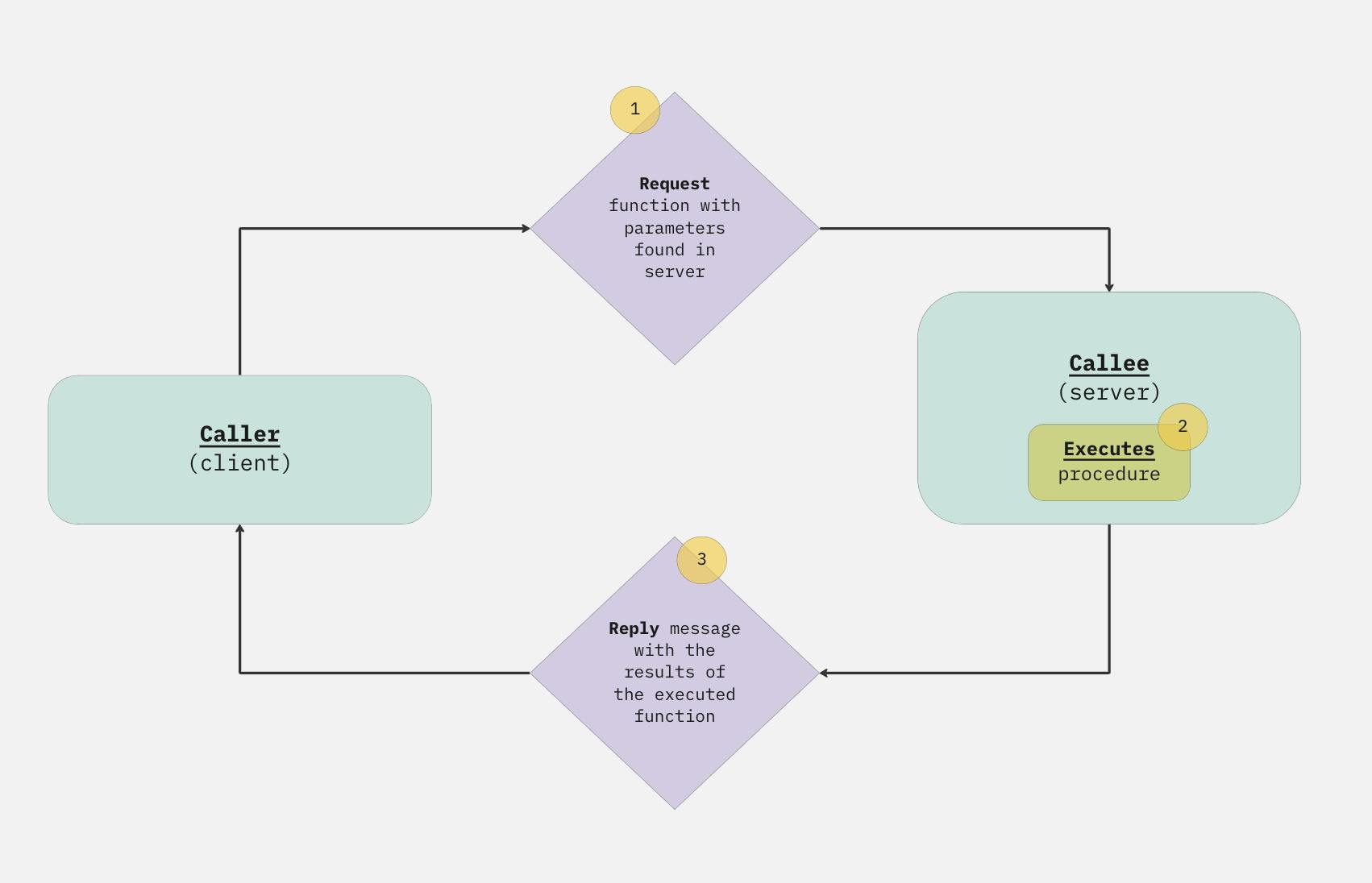
Image 1: RPC model visualisation
So what is special about tRPC ?
tRPC is a tool that leverages the RPC technology, while providing many other flexible features if you are working with Typescript, with one of the selling points being end-to-end type safety.
Considering REST APIs and GraphQL as the most common types of APIs, tRPC can be placed somewhere in between. It is not about resources (unlike REST) but it also has different endpoints (unlike the single endpoint of GraphQL). tRPC is about actions, it focuses on the logic that a request asks the called machine to perform. After all, this is the core idea of the RPC protocol, right? 🤷♀️
Comparing the tools through an example
Let's examine a simple model where users post messages on a board: any user can write a message, post it (which saves it to the database), and then see it on the board along with other messages.
(I am going to exclude the REST solution here as being less optimal, and focus on the other two only.)
1 - Using GraphQL
With a GraphQL implementation, we need two models that describe the two entities of the example, one for the User and one for the Message. These will be declared in a schema.ts file along with the Query and Mutation types (to be parsed with the gql package - not showing here).
type Query {
users: [User!]!
user(id: ID!): User
messages: [Message!]!
message(id: ID!): Message
}
type Mutation {
createMessage(text: String!,
authorId: ID!): Message!
}
type User {
id: ID!
username: String!
email: String!
messages: [Message!]
}
type Message {
id: ID!
text: String!
author: User!
}
The code above defines the object types but does no more than that. It provides no interaction between them. For a user to be able to actually create a message, we have to implement the resolver function for the createMessage mutation.
An example implementation of this resolver, while using Prisma as our ORM, would look like that:
Mutation: {
createMessage: async (_, { text, authorId }, { ctx }) => {
return await prisma.message.create({
data: {
text,
author: {
connect: {
id: authorId,
},
},
},
})
},
}
Here, we created a new record in the message table of the database. We set its text field to text and connected it with its author through the authorId.
Now that we have a resolver for creating messages, we just have to call it from the front end whenever we need it. We can do that with any GraphQL client library that provides queries and mutation hooks.
On the client side, we still have to create the query or mutation fields of course, as well as any arguments, in case we need to filter data or create new:
import gql from 'graphql-tag';
import { useQuery } from '@apollo/react-hooks';
const GET_MESSAGES = gql`
query {
messages {
id
text
}
}
`;
const MessagesPage = () => {
const { loading, error, data } = useQuery(GET_MESSAGES);
if (loading) return <p>Loading...</p>;
if (error) return <p>Error :(</p>;
return (
<ul>
{data.messages.map(message => (
<li key={message.id}>{message.text}</li>
))}
</ul>
);
}
export default MessagesPage;
With this code, we are rendering an array of message objects, with each one containing an id and text field.
And here we have the main journey of data being exchanged between a client and a server with the help of GraphQL. 🥳
2 - Using tRPC
tRPC does not rely on a schema. Instead, we are going to create routes. These refer to the endpoints that are exposed by the server and allow clients to make remote procedure calls to it.
A unique combination of a method name and an endpoint URL defines each route. For example, the /api/message/createMessage refers to the createMessage method of the message route. The server uses this information to map the client request to the correct handler function that is going to process it.
Here we define a route called createMessage, which is responsible for creating a new text message, given an authorId and a text as inputs:
const messages = router({
createMessage: t.procedure
.input(z.object({ text: z.string(), authorId: string() }))
.mutation(async () => {
return await prisma.message.create({
data: {
text,
author: {
connect: {
id: authorId,
},
},
},
})
}),
})
export default messages
(The router, t, and procedure are provided by the tRPC library, whereas the z comes from the zod library, for field validation.)
As we can see here, the core of the mutation function is doing exactly what the GraphQL resolver does. In this example, we achieve the same result, but with half the code! ⚡️
To use this endpoint in the client, we have to import the trpc object provided by the tRPC package. We can then use the function (here of mutation type) by chaining the routes as methods, like so:
import { trpc } from "../utils/trpc"
import { useQueryClient } from "@tanstack/react-query"
const useMessages = () => {
const qc = useQueryClient()
const { mutate: createMessage } = trpc.messages.createMessage.useMutation();
return {
createMessage
}
}
export default useMessages
Now we are ready to use the createMessage function anywhere in our application :)

Is that all?
Well, not really!
You might rightly think that just reducing the code is not enough of an argument to change your stack. Having less code for a certain functionality is surely great, but there are other criteria to consider that are specific to each project and will ultimately guide you to the right choice.
Having always used GraphQL I was sceptical when I had to make such a quick switch just for this one company project. After all, GraphQL provides a complete solution for this type of problems, and when used with tools like Apollo, it makes the development process smooth and enjoyable.
Trying resolvers or endpoints in isolation 🧪
Being able to have a high overview of the schema, as well as testing the resolver functions in isolation is always a nice experience. It gives me confidence when I have to scale up, add more features, track bugs, access past iterations of my schema and changelogs, etc. It is certainly a fair trade-off for the extra wiring up I have to do with GraphQL at the beginning of a project.
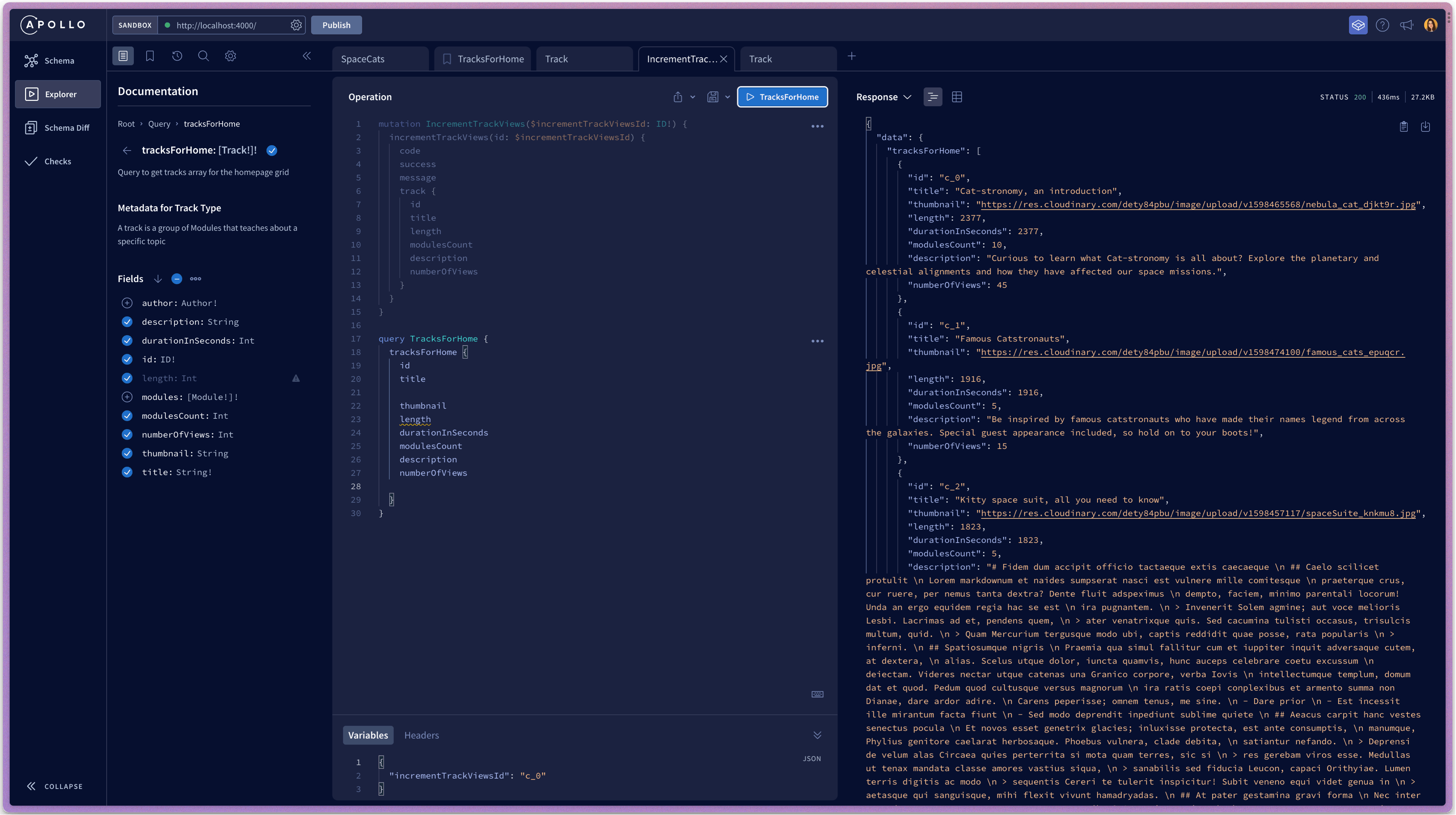
Image 2: Explorer in Apollo Server - here we write and test our GraphQL resolvers
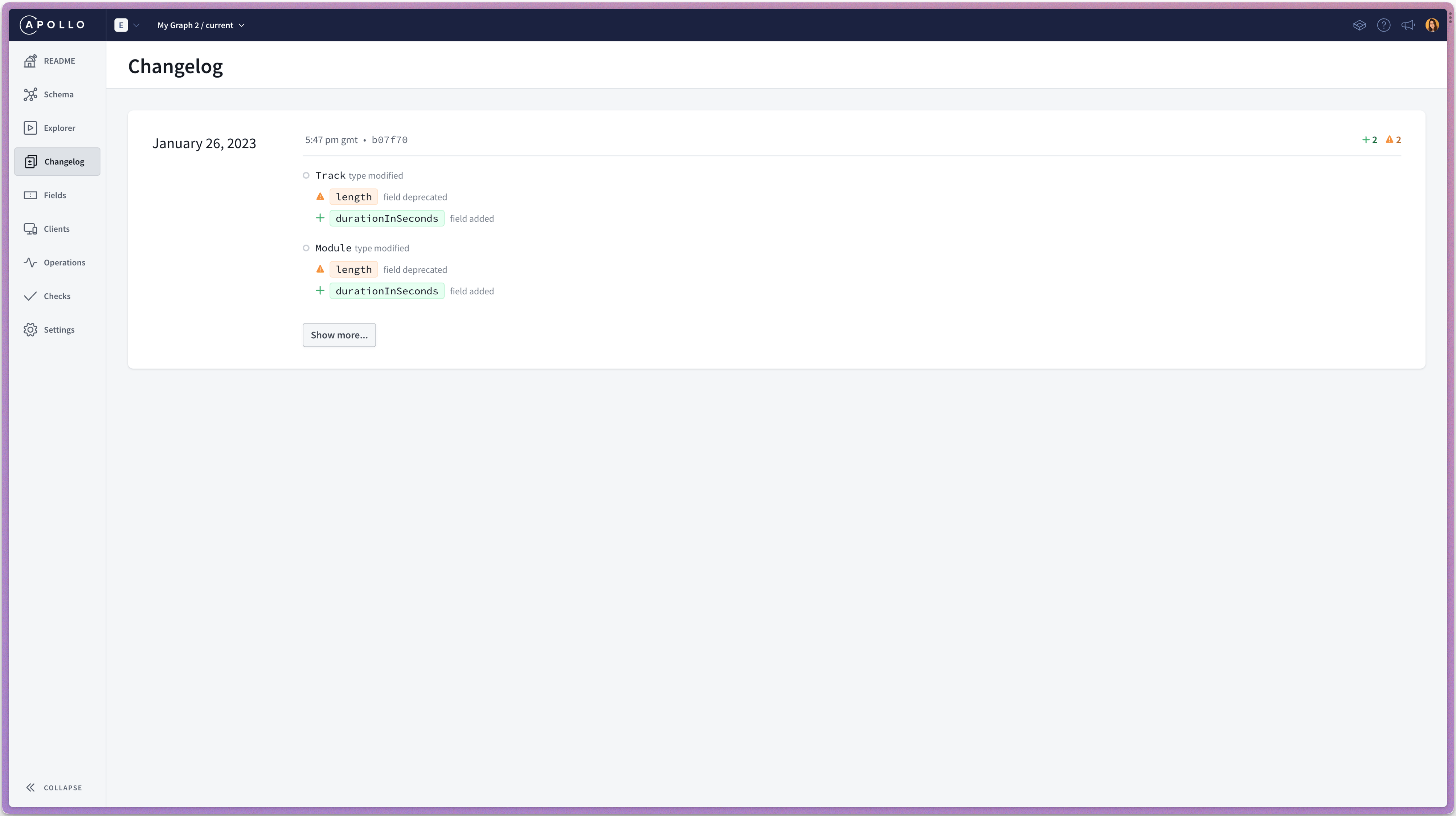
Image 3: Changelog in Apollo Server - all past changes of our schema appear here
tRPC does not provide something similar, but every endpoint is exposed and can be accessed just like any regular URL. The result will appear on the screen in a JSON format, like so:
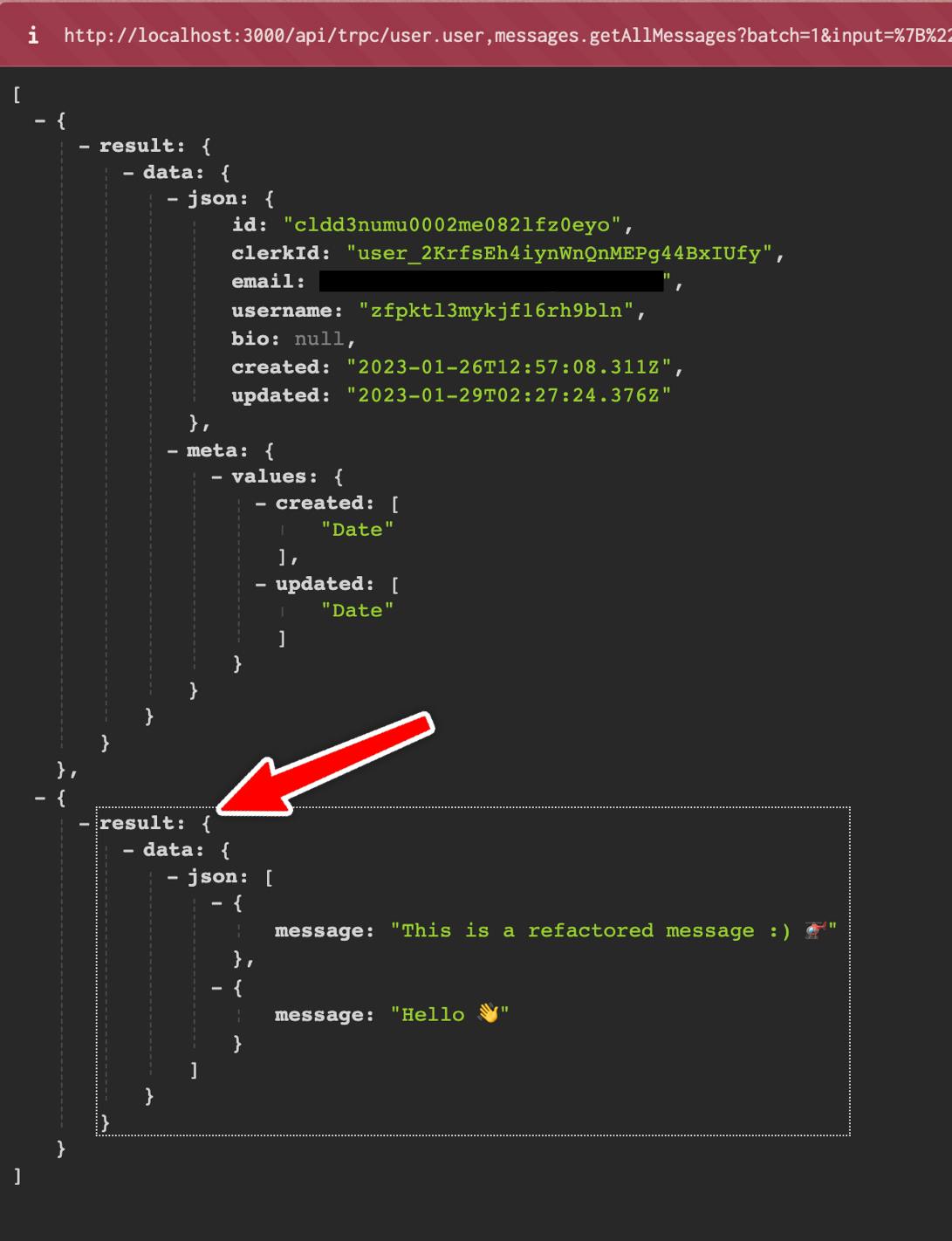
Image 4: Endpoint created in tRPC application
(For a fuller experience you can use external packages, like trpc-playground, that provide a platform to test your endpoints in a more intuitive way.)
Type safety 🦺
GraphQL is language-agnostic (which is fantastic!), but in this particular case it does not fully take advantage of TypeScript.
This leads us to recreate all these types on the client manually, which is timely and error-prone. To avoid this, we need a type generation tool (e.g. graphql-code-generator), that can generate all these types in the front end based on the schema. Only after this process do we have type safety and can use the queries and mutations available in the client. 🤓
With tRPC though, there is no such need! The tool takes advantage of the fact that in a full-stack TypeScript project, we can share types between the client and the server.
When we set up tRPC on the server, we explicitly export the type of the router:
export type AppRouter = typeof appRouter
And, simply enough, we import it in our client:
import type { AppRouter } from "@messaging/api"
And just like that, we have real-time checks and auto-completion on the client ✨
Potential errors like this ⬇️ can be easily captured!

In the screenshot above, I am trying to access the users property instead of user. Since this does not exist, I get a TypeScript error so I can correct it.
Now everything looks good 🙂

Payload size 📦
Another important factor when considering these two tools is the payload size.
GraphQL allows the client to request only specific data, structured exactly as needed, rather than getting a fixed set of it. This of course results in smaller payloads compared to REST because the client receives exactly what they asked and not any extra, unnecessary data of a larger payload.
On the other hand, tRPC can serialise data in a compact binary format. That means that complex data structures are encoded in binary format, which results in much smaller payload sizes compared to the traditional JSON. In tRPC we can also add data transformers to serialise the responses as well as input arguments in various formats, which provides extra flexibility.
Conclusion
Ultimately, choosing one out of the two technologies is a decision that should be made based on your project's current and future needs, as well as your personal preferences.
Both tools provide excellent and flexible solutions but definitely shine under different circumstances. If you feel one is better than the other for your specific case, just go with it!
It is also worth noting, that sometimes, familiarity and mastery of a specific technology can be enough of an argument to stick with it and not jump to other things. The developer should be in control of the tool and not the other way around :)